
Seit 2018 bestimme ich meinen Lauf-FTP. Damals hatte ich mir einen Stryd gekauft, den mit der drahtlosen Ladestation, auf die man ihn einfach nur drauflegt. Der hatte noch keinen "Air Power", aber es war auch nicht mehr der Prototyp, den man sich noch um die Brust schnallen musste. Seitdem laufe ich nach Wattleistung.

Mein erster Stryd am Schuh, September 2019. Ein halbes Kinderleben her.
Nach 8 Jahren Laufen nach Wattleistung und dem Gefühl, welches ich dafür über die Zeit entwickelt habe, bin ich heute in der Lage, meinen FTP aus dem Bauch heraus zu schätzen. Voraussetzung dafür ist aber, daß ich einen etwas intensiveren Lauf gemacht habe und einigermaßen im Training bin. Sonst fehlt die Referenz und das Körpergefühl ist nicht kalibriert.
Meine eigene FTP-Schätzung
Nach einer längeren Pause mit ernsthaftem Training bin ich nun seit 2 Monaten wieder im Aufbau. Gestern habe ich mal ein paar Schwellenwertintervalle gemacht: 3 × 6 Minuten bei ca. 85–88% der maximalen Herzfrequenz, bewusst kontrolliert, kein Vollgas.
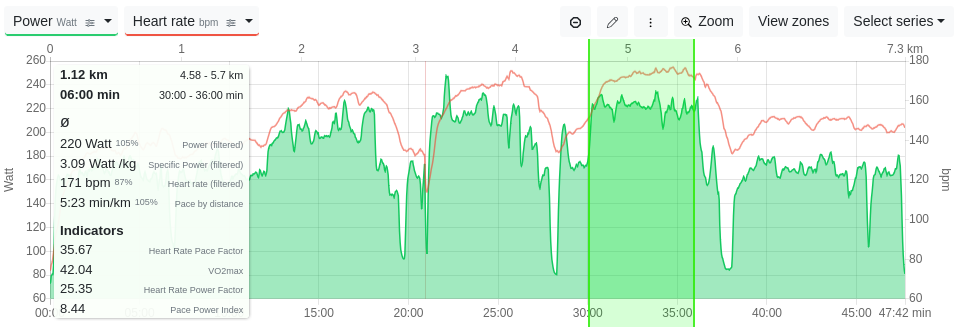
Die drei Schwellenwertintervalle meines Laufes in Tredict mit Watt-Leistung und Herzfrequenz in der Zeitserie.
Ehrlich gesagt habe ich die Intervalle auch recht unsauber ausgeführt. Beim ersten war ich eigentlich zu langsam, beim zweiten zu ungleichmäßig, aber das dritte war ganz gut. Das kennt Ihr vielleicht.
Also hier ist die Vorlage, meine persönliche FTP-Schätzung: Nach dem Lauf gestern mit 3 × 6 Minuten Schwellenwertintervallen schätze ich einfach mal, daß mein aktueller FTP bei 225 Watt liegt. Das ist die Leistung, die ich konstant eine Stunde lang aufrechterhalten könnte.
Jetzt wollen wir mal sehen, was die KI-Modelle dazu sagen, wenn sie sich meinen gestrigen Lauf und ein paar Läufe davor anschauen.
Und Ihr müsst mir glauben, ich verspreche Euch: Ich habe meine eigene Schätzung vorgenommen, bevor ich die Tests mit den Modellen gemacht habe.
Der Test: Ein Prompt, sechs Modelle
Alle sechs KI-Modelle haben über den Tredict-MCP-Server oder die offizielle Tredict ChatGPT App Zugriff auf meine Trainingsdaten erhalten. Jedes Modell hat den gleichen Prompt bekommen:
@tredict Bitte bestimme meinen aktuellen Functional Threshold Power (60-Minuten-Leistung) für das Laufen. Schaue Dir dazu die Zeitreihen meines gestrigen Laufs an, insbesondere Leistung und Herzfrequenz. Der Lauf enthält 3 Schwellenwertintervalle, die bewusst zurückgehalten wurden, also nicht mit vollem Einsatz gelaufen. Verwende meine konfigurierte HRmax in den Kapazitätswerten als obere Herzfrequenzgrenze und extrapoliere, um die tatsächliche Schwellenleistung zu schätzen. Für weitere Informationen schaue Dir auch die letzten 2 Wochen meines Trainings an.
Die Ergebnisse
| Modell (LLM) | FTP-Schätzung (60 min) | Chatverlauf | |
|---|---|---|---|
| Claude.ai - Opus 4.6 | 220–225 W LLM-Empfehlung: Kann auf 225 W gesetzt werden |
Öffnen | ✓ |
| ChatGPT - GPT-5.4 mit Go | ~225 W | Öffnen | ✓ |
| Perplexity - Kimi K2.6 | 218–225 W LLM-Empfehlung: Sollte auf 225 W gesetzt werden |
Öffnen | ✓ |
| Perplexity - Sonar 2 | ~230 W LLM-Empfehlung: Mindestens auf 225 W setzen |
Öffnen | ✓ |
| Perplexity - Gemini 3.1 Pro Thinking | 232–235 W | Öffnen | ✗ |
| Claude.ai - Sonnet 4.6 | 235–245 W LLM-Empfehlung: Sollte auf 235 W gesetzt werden |
Öffnen | ✗ |
Das ist doch cool! Die meisten Modelle haben den FTP um die 225 Watt bestimmt, genau da, wo auch meine eigene Bauchschätzung liegt.
Meine Meinung dazu
Jetzt kommt eine persönliche Meinung zum FTP, die vielleicht bei manchen sauer aufstößt: Man kann den FTP nicht exakt auf das Watt genau bestimmen. Der FTP ist von so vielen Faktoren abhängig, wie Tagesform, Schlaf, Ernährung, Temperatur und Strecke, daß ein Bereich von-bis die einzig ehrliche Antwort ist. Also z.B. 220–230 Watt. Macht in der Mitte 225 Watt. Mit irgendwas muss man ja arbeiten während des Trainings.
Ich finde, die meisten Modelle haben sich gut geschlagen! Allerdings mit Gemini 3.1 Pro und Sonnet 4.6 als negative Ausreißer, wo der bestimmte FTP doch etwas hoch war. Am meisten negativ überrascht hat mich Sonnet 4.6. Oder waren das etwa die Modelle, welche korrekt lagen? Nein, ich denke nicht. ;-)
Am positivsten überrascht hat mich ChatGPT mit GPT-5.4: kurzes, aber knackiges Reasoning und direkt auf den Punkt. Und Kimi K2.6 auf Perplexity hat mich mit einem sauberen, mathematisch nachvollziehbaren Reasoning ebenfalls beeindruckt.
Wie die Modelle vorgegangen sind
Alle Modelle haben über den Tredict-MCP-Server die Trainingsdaten abgerufen: die Zeitserien des gestrigen Laufs (Leistung und Herzfrequenz in 10-Sekunden-Intervallen), meine konfigurierten Kapazitätswerte (HRmax: 197 bpm, HRlth: 172 bpm) und die Trainingshistorie der letzten zwei Wochen. Auf dieser Datenbasis haben sie dann jeweils ihre Analyse durchgeführt. Die grundsätzliche Herangehensweise war bei fast allen Modellen erstaunlich ähnlich:
1. Intervalle identifizieren. Alle Modelle haben die drei Schwellenwertintervalle in der Zeitserie korrekt erkannt und jeweils die durchschnittliche Leistung und Herzfrequenz extrahiert. Die Werte lagen je nach Modell bei ca. 202–204 W (Intervall 1), 213–216 W (Intervall 2) und 219–221 W (Intervall 3).
2. Herzfrequenz-Leistungs-Beziehung modellieren. Die meisten Modelle haben eine lineare Regression über die drei Intervall-Datenpunkte gerechnet, um die Beziehung zwischen Herzfrequenz und Leistung zu quantifizieren.
3. Extrapolation auf die Laktatschwelle. Hier liegt der entscheidende Schritt: Bei welcher Leistung würde ich meine konfigurierte Laktatschwellen-Herzfrequenz (172 bpm) erreichen? Das dritte Intervall lag mit 173 bpm bereits fast genau an der Schwelle bei ca. 220 W, und da die Intervalle bewusst zurückgehalten wurden, haben die Modelle eine kleine Aufwärtskorrektur von 2–6% angewendet. Wie man seinen persönlichen Laktatschwellenwert ganz ohne KI bestimmt, erkläre ich ausführlich im Artikel Laktatschwellwert, FTP und FTPa automatisch bestimmen. Und testweise habe ich Kimi K2.6 zusätzlich noch gefragt, ob es mir die Laktatschwellen-Herzfrequenz direkt aus dem Lauf berechnen kann, und Kimi kam auf 170–172 bpm. Genau so wie es bei mir in Tredict konfiguriert ist.
ChatGPT (GPT-5.4 mit Go)
ChatGPT hat eine tabellarische Herzfrequenz-Leistungs-Zuordnung aus den saubersten Abschnitten der Intervalle erstellt. Bei der Laktatschwellen-Herzfrequenz von ~172 bpm lag die beobachtete Leistung bei 210–220 W. Mit einer Aufwärtskorrektur von 3–6% für die zurückgehaltene Anstrengung kam ChatGPT auf 221–228 W und hat sich dann auf ~225 W festgelegt. Ergänzend wurde das Ergebnis mit den letzten zwei Trainingswochen abgeglichen: keine maximalen Belastungen, aber der vorherige FTP von 210 W war offensichtlich veraltet.
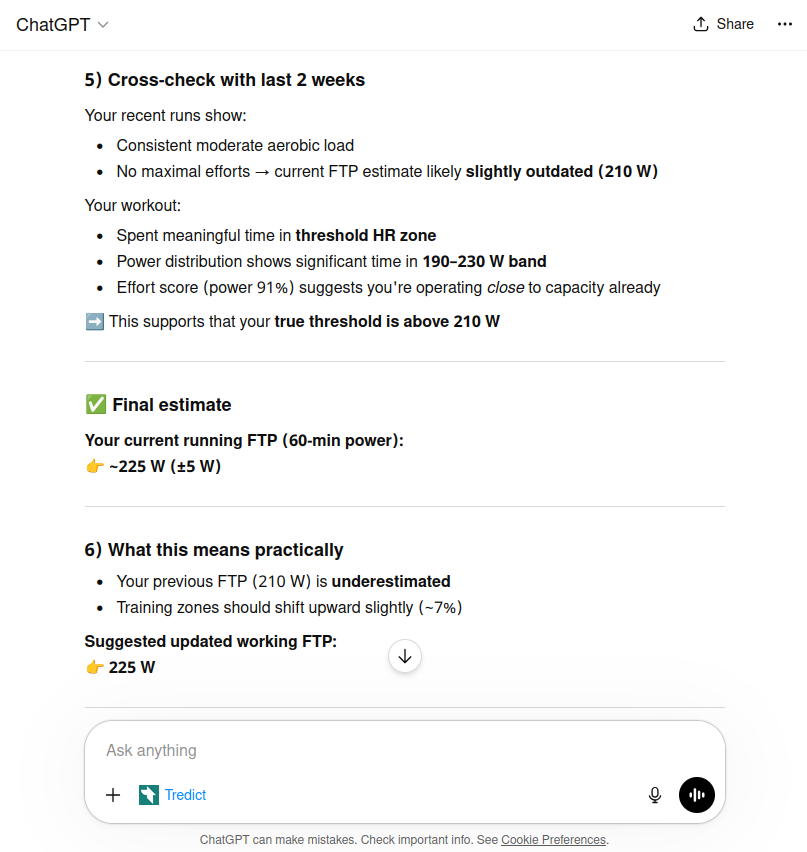
ChatGPT (GPT-5.4) bestimmt den FTP auf ~225 W und empfiehlt eine Anpassung der Trainingszonen.
Claude Opus 4.6
Opus 4.6 hat parallel die Kapazitätswerte, die Aktivitätsdetails und die Trainingshistorie abgerufen und die 10-Sekunden-Zeitserie programmatisch ausgewertet. Die drei Intervalle zeigten: 204 W bei 81% HRmax, 216 W bei 85% und 220 W bei 88%. Daraus wurde eine lineare Regression berechnet (P = 1.21 × HR + 11.3), die bei der Laktatschwelle von 172 bpm exakt 220 W ergab. Mit 2–3% Aufwärtskorrektur für die zurückgehaltene Anstrengung empfiehlt Opus 220–225 W. Besonders schön: Claude hat daraus direkt eine interaktive Visualisierung mit Regressionsgerade und Intervall-Übersicht gebaut.
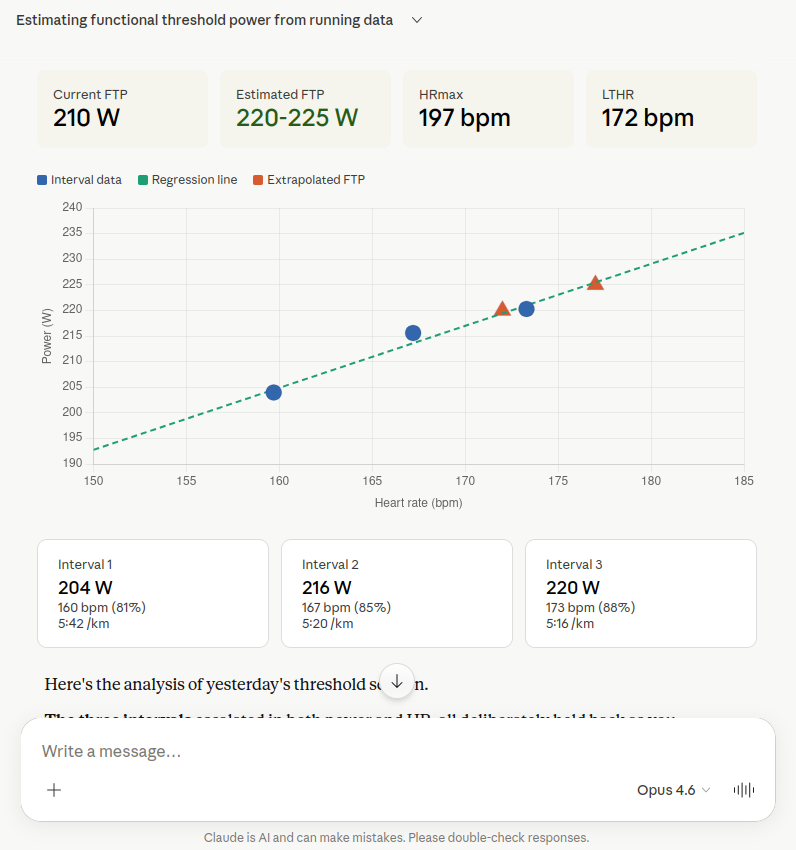
Claude Opus 4.6 erstellt eine interaktive Visualisierung mit Regressionsgerade und bestimmt den FTP auf 220–225 W.
Kimi K2.6 (auf Perplexity)
Kimi K2.6 hat den mathematisch saubersten Weg gewählt. Die drei Intervalle wurden präzise mit Zeitbereichen extrahiert und die kardiale Drift quantifiziert: Die Herzfrequenz stieg über die drei Intervalle um +12,8 bpm, während die Leistung nur um +17 W zunahm, typisch für bewusst kontrollierte Belastungen. Die lineare Regression (HR = 0,731 × Power + 10,26) ergab bei der Laktatschwelle von 172 bpm eine Leistung von (172 − 10,26) / 0,731 ≈ 221 W. Kimi empfiehlt einen Bereich von 218–225 W und merkt an, daß der alte FTP von 210 W um ca. 5% zu niedrig liegt.

Kimi K2.6 berechnet den FTP mathematisch sauber per linearer Regression auf ~221 W (218–225 W).
Sonar 2 und Gemini 3.1 Pro Thinking (auf Perplexity)
Sonar 2 kam auf ~230 W und riet dazu, den FTP mindestens auf 225 W zu setzen. Gemini 3.1 Pro Thinking extrapolierte mit 232–235 W am weitesten nach oben. Beide Modelle haben die gleichen Trainingsdaten über den Tredict-MCP-Server abgerufen, aber aggressiver nach oben korrigiert. Die vollständigen Chatverläufe sind oben in der Tabelle verlinkt.
Claude Sonnet 4.6, der Ausreißer
Sonnet 4.6 ist mit 235–245 W der deutlichste Ausreißer nach oben. Sonnet hat die gleichen drei Intervalle identifiziert (203 W / 156 bpm, 216 W / 167 bpm, 221 W / 173 bpm) und daraus eine lineare Regression mit einer Steigung von ~1,6 W/bpm berechnet. Im Unterschied zu den anderen Modellen hat Sonnet aber nicht bis zur Laktatschwelle (172 bpm) extrapoliert, sondern bis zur maximalen Herzfrequenz (197 bpm): +24 bpm × 1,6 = +38 W, also ~259 W bei HRmax. Das ist ein methodischer Fehler! Davon wurde dann ein 6–8% Abschlag für die 60-Minuten-Nachhaltigkeit abgezogen, was auf 238–243 W führt. Als konservativen Arbeitswert empfiehlt Sonnet 235 W. Die Rechnung über die HRmax statt einer direkten Extrapolation auf HRlth ist der Grund für den höheren und falschen Schätzwert. Als Entschädigung zeigte Claude aber dafür die Zeitserien in einem Diagramm an. Denke ich dann beim nächsten 10K-Wettkampf dran, wenn ich auf 8 Kilometer zusammenbreche, hehe.
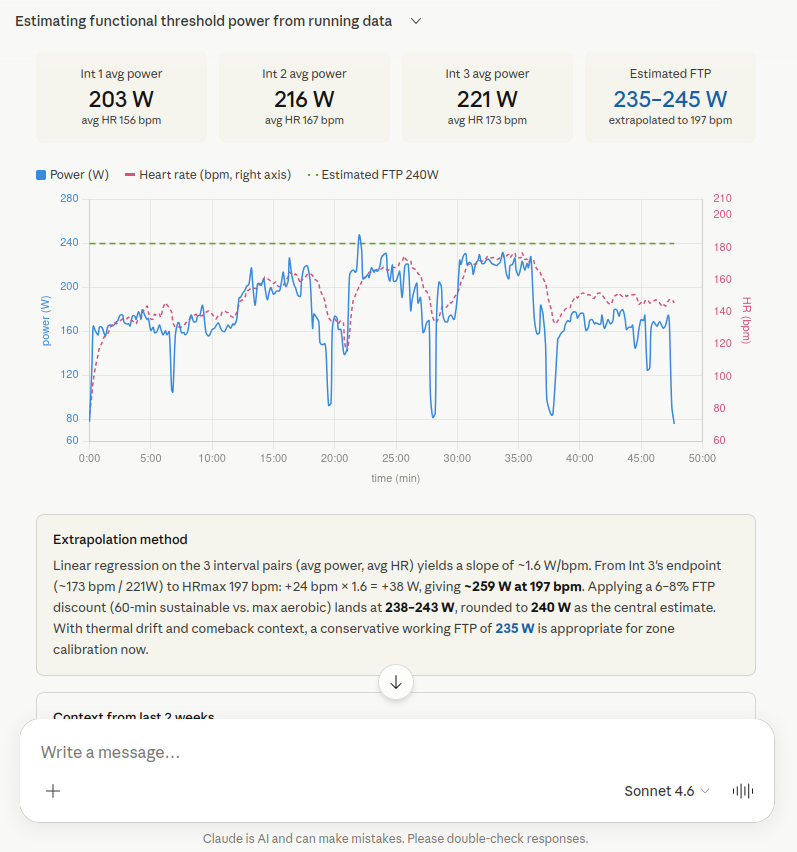
Sonnet 4.6 extrapoliert bis zur HRmax statt zur HRlth und landet mit 235–245 W deutlich über den anderen Modellen. Das war methodisch falsch.
Warum liegen nicht alle Modelle gleich?
Die Intervall-Erkennung und die lineare Regression waren bei allen Modellen nahezu identisch. Der entscheidende Unterschied liegt im letzten Rechenschritt, wohin extrapoliert werden soll. Und welche Korrekturfaktoren angewendet werden. Diese Entscheidungen trifft das LLM auf Basis seiner Trainingsdaten und seiner internen Einstellungen, wie z.B. der sogenannten "Temperatur", die den Grad der Kreativität - was nichts anderes als ein gewollter Zufall auf einer Kurve ist - bei der Antwortgenerierung steuert. Sonnet hat bis zur maximalen Herzfrequenz extrapoliert, die anderen Modelle korrekt bis zur Laktatschwelle. Sonnet hat dabei einen methodischen Fehler begangen. Extrapoliert wird auf die Laktatschwellen-Herzfrequenz, nicht auf die maximale Herzfrequenz. Gesucht ist die 60-Minuten-Leistung im Bereich der Laktatschwelle, und die liegt nicht an der HRmax. Das ist der Grund für den deutlich überhöhten Schätzwert.
Der Vorteil gegenüber einem reinen Algorithmus ist, daß die Modelle ihre Herleitung zeigen. Man kann nachlesen, wie das Ergebnis zustande kam, und selbst einschätzen, ob die Logik Sinn ergibt. Wenn einem ein Wert zu hoch oder zu niedrig vorkommt, sieht man im Reasoning sofort warum und kann im selben Chat gezielt nachfragen. Das erfordert kein Expertenwissen, aber ein gewisses Maß an Trainingserfahrung, um zu erkennen, ob ein FTP-Wert realistisch ist oder nicht. Für den blutigen Anfänger kann ich diese Methode also nicht unbedingt empfehlen. Auf der anderen Seite: Versuch macht kluch!
Genaues Prompten und Nachfragen
Der Prompt war bewusst detailliert formuliert. Je präziser die Anweisung, desto besser das Ergebnis. Und wenn ein Modell die Aufgabe nicht richtig versteht oder ein zweifelhaftes Ergebnis liefert, kann man einfach nachfragen und korrigieren. Manche Modelle "überdenken" dann ihren Ansatz und kommen doch beim richtigen Ergebnis raus. Im Falle von Sonnet war der Prompt wohl noch zu ungenau und man hätte nachprompten können.
Fazit
Acht Jahre Laufen nach Wattleistung haben mir ein Gefühl für meinen FTP gegeben, das offenbar recht gut kalibriert ist, und die KI-Modelle bestätigen das. Vier von sechs Modellen landeten in einem Bereich von 218–230 W, also genau dort, wo auch meine eigene Schätzung von 225 W liegt. Zwei Modelle lagen mit 232–245 W höher, aber auch da zeigt die transparente Herleitung sofort, warum: bei Gemini aggressivere Korrekturfaktoren, bei Sonnet ein methodischer Fehler beim Extrapolationsziel.
Besonders beeindruckt hat mich, daß die Modelle nicht einfach nur eine Zahl ausgeben, sondern ihre Herleitung transparent darstellen: Intervalle identifizieren, Regressionen berechnen, Korrekturfaktoren begründen. Das macht die Ergebnisse nachvollziehbar und überprüfbar. Wer etwas Erfahrung mit leistungsbasiertem Training hat, kann die Analyse der Modelle kritisch bewerten und einordnen. Und genau so sollte man KI-generierte Ergebnisse auch behandeln: nicht blind übernehmen, sondern die Herleitung lesen, das Ergebnis hinterfragen und bei Bedarf im Chat nachsteuern.
Tredict mit KI und Sportuhren verbinden
Alle sechs KI-Modelle in diesem Test haben die Trainingsdaten über den Tredict-MCP-Server abgerufen. Der MCP-Server ist die Schnittstelle, die es KI-Assistenten wie Claude, ChatGPT, Mistral Le Chat oder Modellen auf Perplexity ermöglicht, auf Deine Trainingshistorie zuzugreifen, Kapazitätswerte zu bestimmen und sogar Trainingspläne direkt in Tredict zu erstellen.
Für ChatGPT gibt es außerdem die offizielle Tredict ChatGPT App, die mit wenigen Klicks und einem kostenlosen ChatGPT-Konto verbunden werden kann:
Zur offiziellen Tredict ChatGPT App
Mehr über den Tredict-MCP-Server und wie Du ihn mit Deinem KI-Assistenten verbindest, findest Du hier:
KI-Assistenten und LLMs mit Hilfe des Tredict-MCP-Server verwenden
Auf der anderen Seite verbindet Tredict Deine Sportuhren und Trainingsgeräte vollautomatisch: Garmin, Coros, Suunto, Wahoo, Polar, Concept2, icTrainer und Watchletic (Apple Watch) synchronisieren Deine ausgeführten Trainings mit Tredict und können strukturierte Workouts direkt auf der Uhr ausführen. Damit schließt sich der Kreis: Von der Sportuhr über Tredict zum KI-Assistenten und zurück.

Felix Gertz
Felix ist Erfinder und Entwickler der Ausdauersport-Trainingsplattform Tredict. Seit 2020 wird Tredict als Plattform für die Trainingsanalyse und Trainingsplanung bei Ausdauersportler:innen und Trainer:innen auf der ganzen Welt geschätzt.